
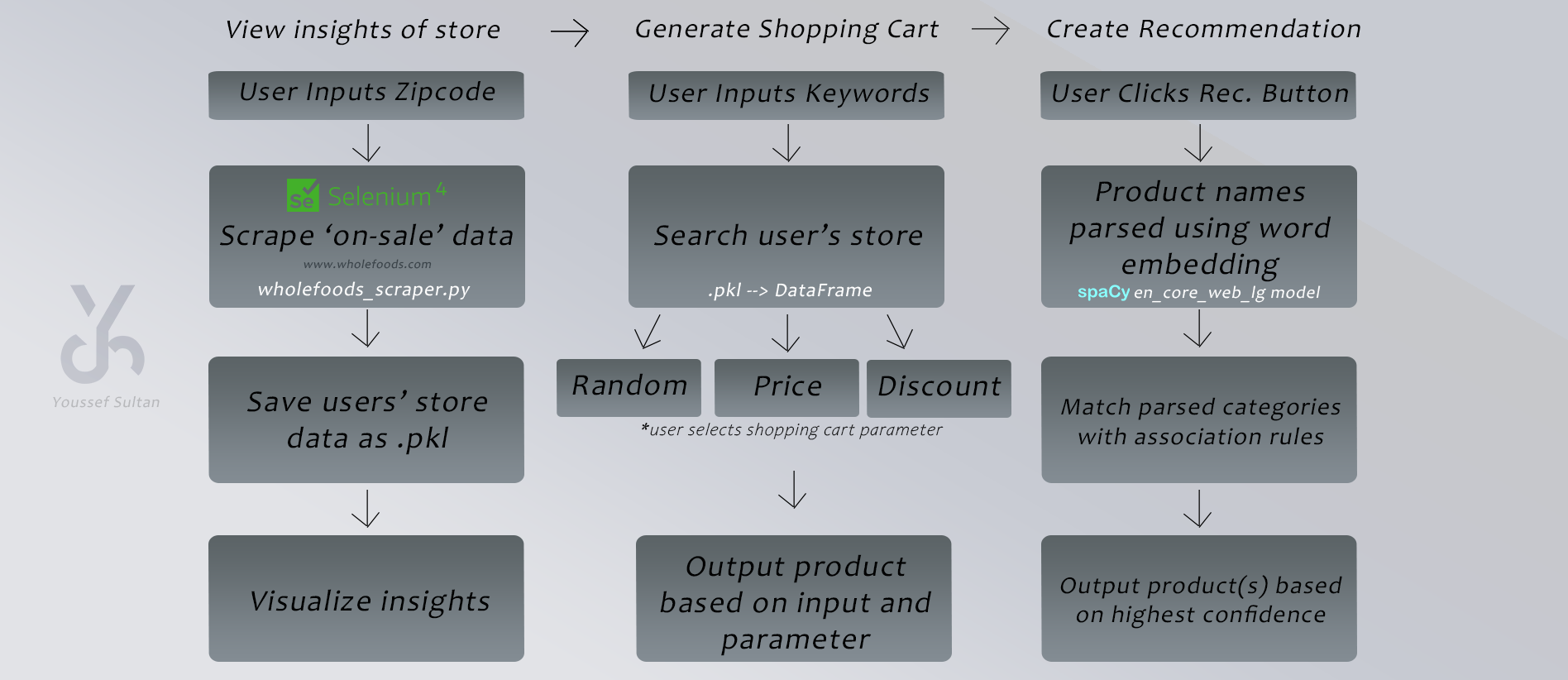
Whole Foods is a grocery store chain that specializes in selling organic foods. Many people who shop at Whole Foods have opted in for Amazon Prime memberships in order to make the most out of their shopping and achieve the best deals amongst all different types of products sold. The one downside is that the Whole Foods website is pretty limited, in that it only shows the highest priced items and lowest priced items on-sale when filtering which doesn’t give the customer much information about everything on-sale at their store as a whole.
Pulling user’s Whole Foods store data:
In order to solve this problem, I created a webscraper using selenium that scrapes Whole Foods website on-sale product data allowing the customer to know the quantity of items on sale at their Whole Foods, which categories are on sale the most, which categories have the highest discounts and their ranges, and many other insights that help the customer know which products have the highest discounts pertaining to their zipcode.
Visualizing store insights:
This allows customers/users to search their store ‘on-sale’ data before shopping to see if the product(s) they are looking for happen to be discounted, and if so which of those products have the highest discounts. This is able to be done manually through a dataset search feature, after the user has queried their own store data, or through a cart generator feature.

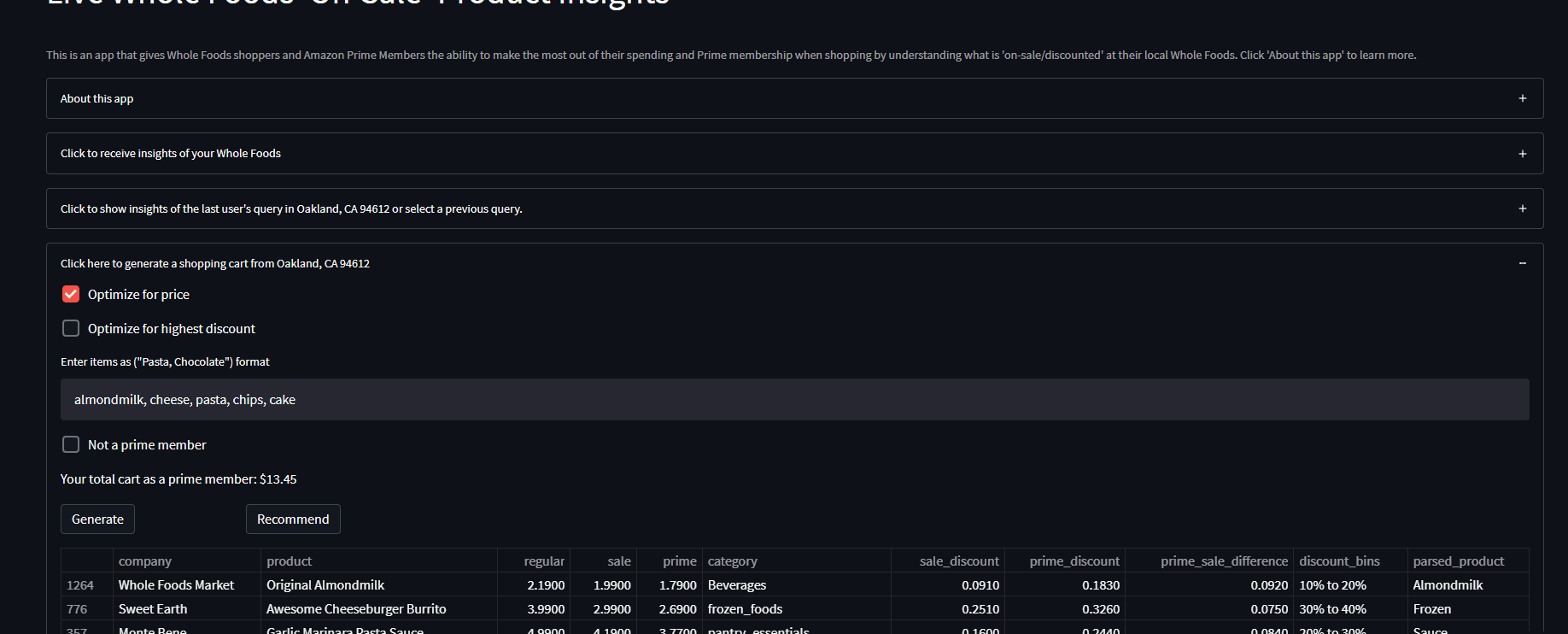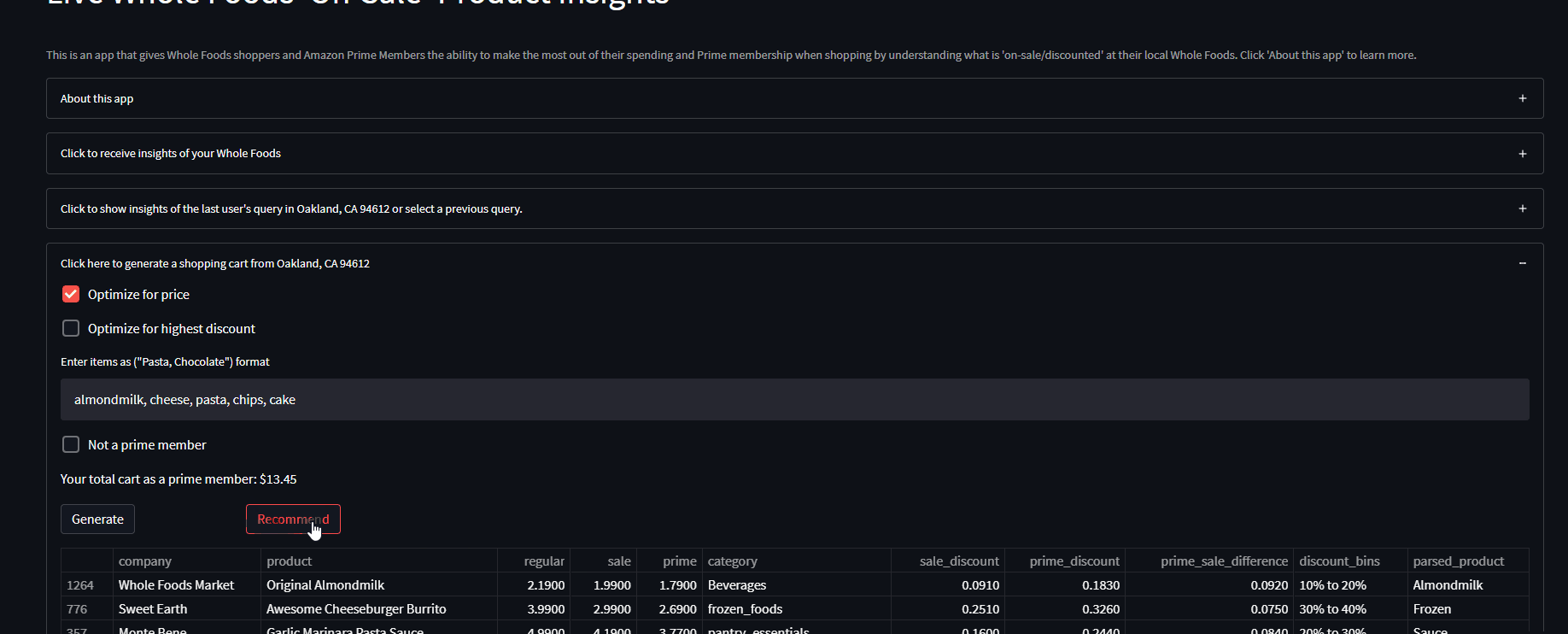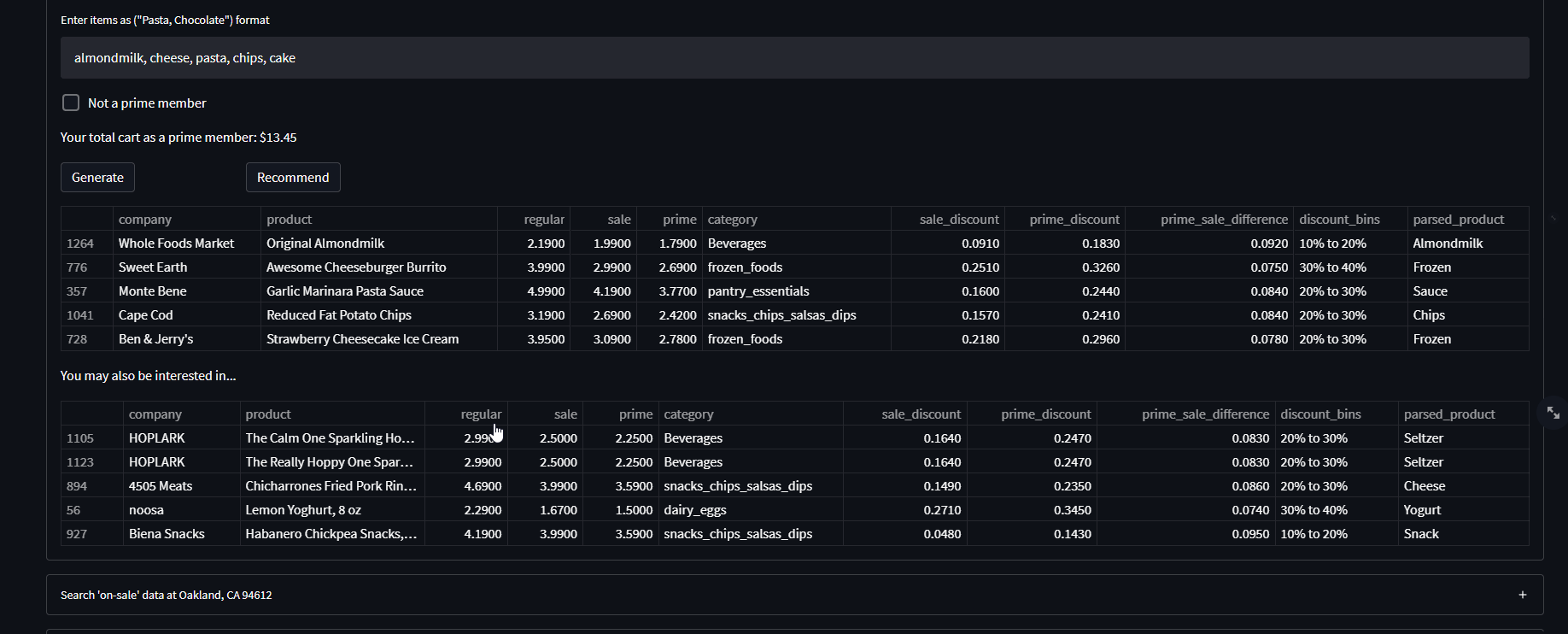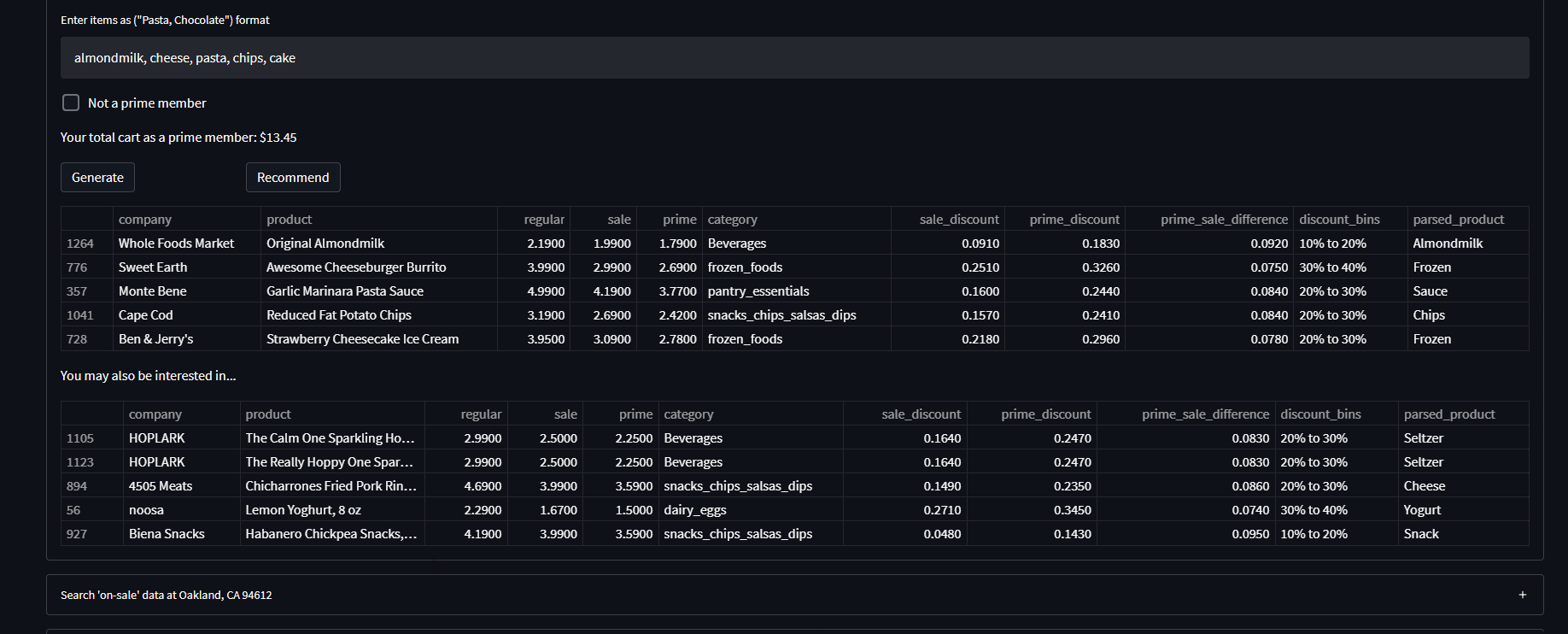
Generate shopping cart:
The cart generator feature generates a shopping cart of items ‘on-sale/discounted’ based on user keyword inputs (‘chocolate, pasta’…) and selected optimization parameter (‘random, price, discount’). If no parameter is selected, any generated cart with pick a random selection of the user’s input from the data.
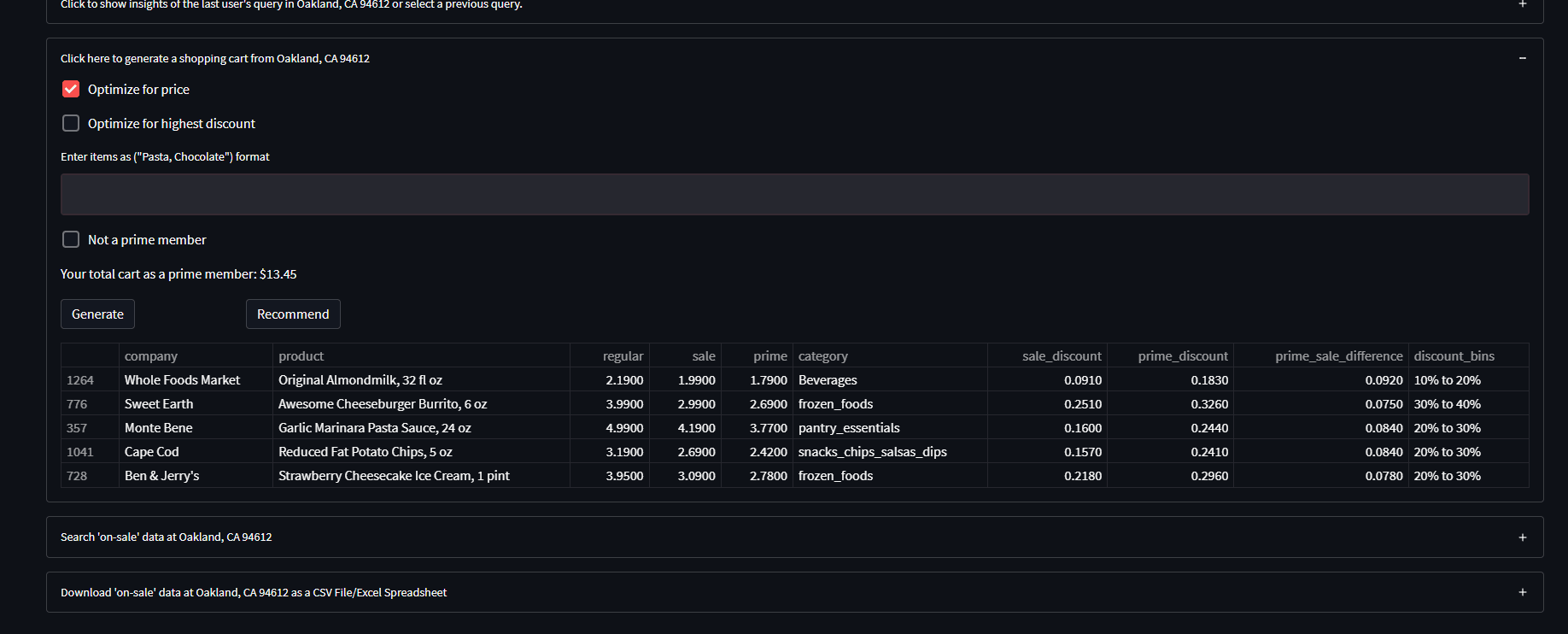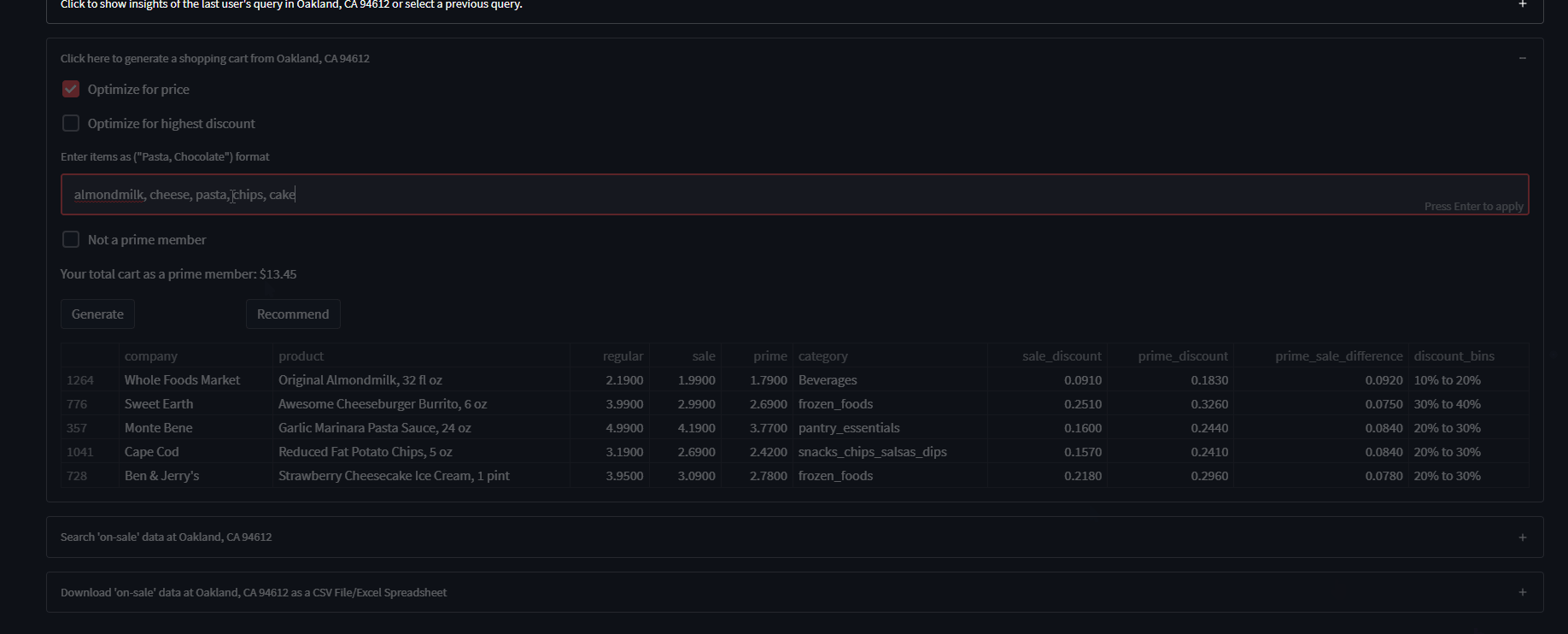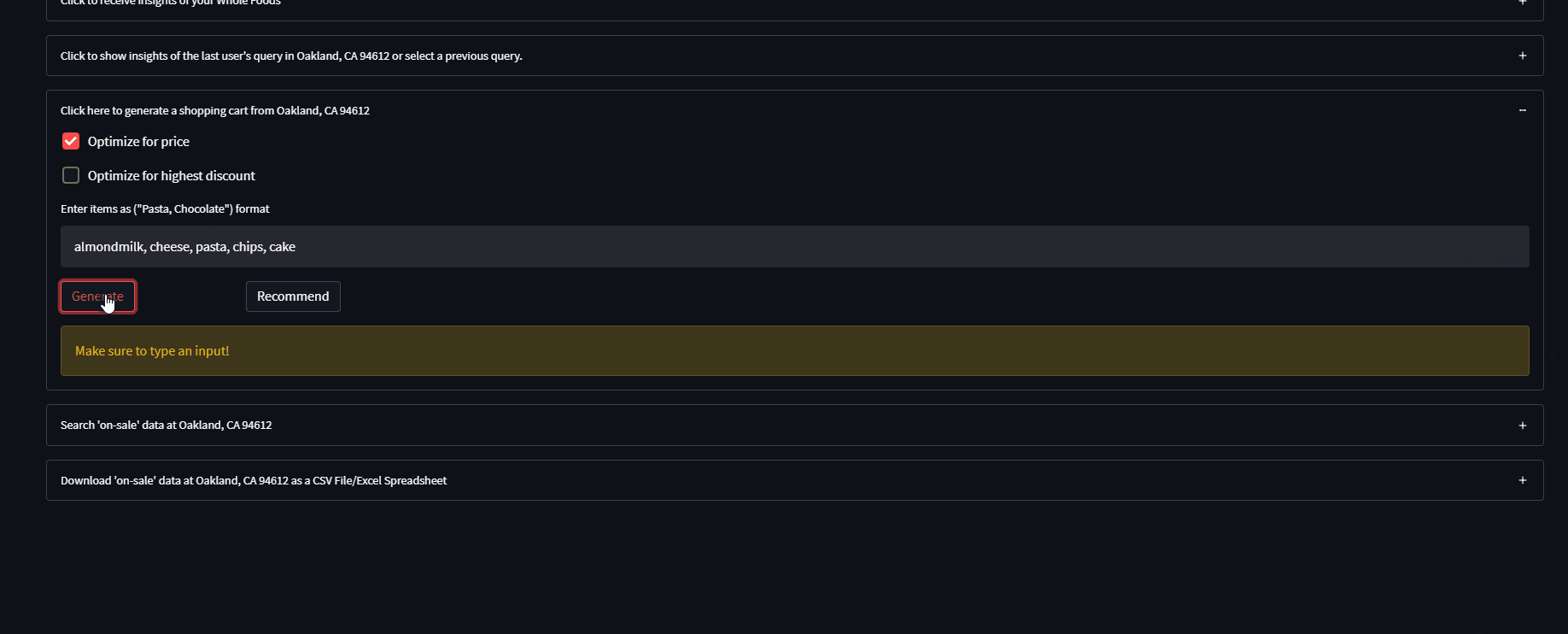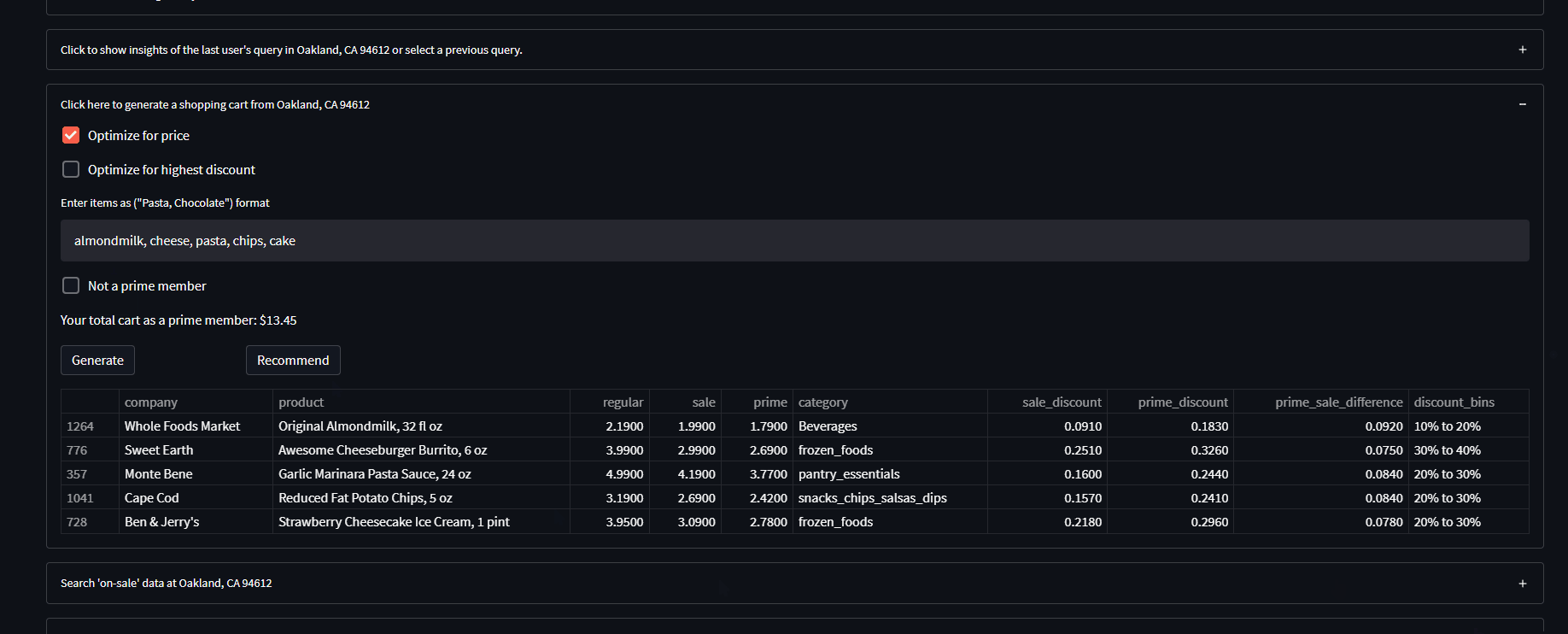
So for ‘chocolate’, if any type of chocolate exists at the user’s Whole Foods and is On-Sale, it will pick a random one and put it in your cart. As for the price optimization parameter, this picks the chocolate with the lowest price possible rather than random, and for the highest discount, it makes sure the item has the highest prime discount percentage. (remember all items in any queried dataset are ONLY on-sale/discounted)
Recommendation system:
I also felt that when I was checking out at Whole Foods normally, I really wanted recommendations or suggestions based on what I usually purchase to try something new but I also wanted those recommendations to be ‘on-sale/discounted’, so I constructed a collaborative filtering based recommendation system approach that uses Instacart’s customer data and item associations to make suggestions to Whole Foods users when having a generated shopping cart.
Based on what is in your shopping cart, say you typed “almondmilk, chocolate” and now you have the lowest priced almondmilk and chocolate in your cart, the recommendation button will recommend one item for each item in your cart based on association rules from Instacart’s customers. This is very useful as it allows the user to have an amazing shopping experience by knowing which items are discounted, having a shopping cart tailored for them, and recommendations to try new things that are still ‘on-sale’
There is also a feature that shows the price of your cart for prime members and non-prime members so there is no discrimination between the two.
The link to the app is at the bottom of this page.
Visual of app features:
Recommendation system approach:

Exploratory Data Analysis on the type of products on sale:
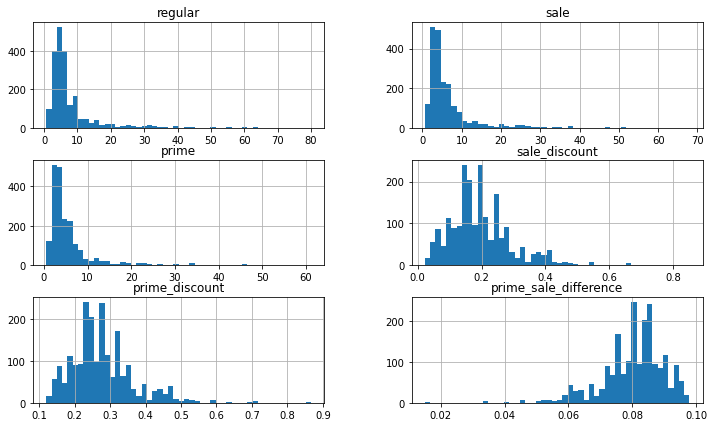
We can see that Prime members get an average discount of 28% off of on-sale items, while non-prime members get an average of 20% off on sale items. This shows that on average, Prime members get their products discounted by 8% more that regular customers. We can also tell that most items that are featured on sale whether that be for non-prime members or prime members, are under $10
For more information on the entirety of the project including algorithms used taxonomy design and signature matching, make sure to check out the links below which include the full source code on Github, end-to-end deployment and exploratory data analysis.
Github: Source Code
Deployment: Streamlit Webapp